Home Page
We take the guesswork out of
your social strategy
Social Video moves fast, and marketers need to anticipate content trends and changing behaviors in order to make smart decisions and act before competitors.
Tubular provides a unified view of the interests and behaviors of social video audiences, helping businesses build a playbook that leads to repeatable success and higher ROI.






The world's largest database of social video insights
1
11
B
Videos across social platforms
1
32
M
Creators including media, brands, and influencers
.1
1
M
Categories & Topics organizing social video
.3
3
B
Consumers' viewership and digital activity
Tubular Solutions
Our Clients

Media
Top media companies trust Tubular to help grow a larger global audience, sell ads more effectively, and stay ahead of the competition.
Media

Brands
Household brand names use Tubular to reach their audience in authentic ways and optimize owned & earned campaigns on social video.
Brands

Agencies
Media & creative agencies rely on Tubular social video intelligence to serve Fortune 500 clients with data-driven guidance, because missing a trend is expensive.
Agencies











"The Tubular taxonomy makes it easy to spot some of the top performing categories, subcategories, and whitespace opportunities when we’re trying to innovate in new areas."
Jon Birchall, Director of Editorial Strategy, LADbible Group
Our secret sauce

Real behavior data
We source real behavior data from billions of people around the globe. We never rely on surveys, cookies, or pixels.

Unmatched scale
With more than 10 years of expertise in social video, we have the most social video data to help you see the big picture.
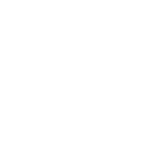
Impeccably organized
Only Tubular combines a cross-platforms view with proprietary classification tech. We’ve simplified & organized the social video universe all in one place.

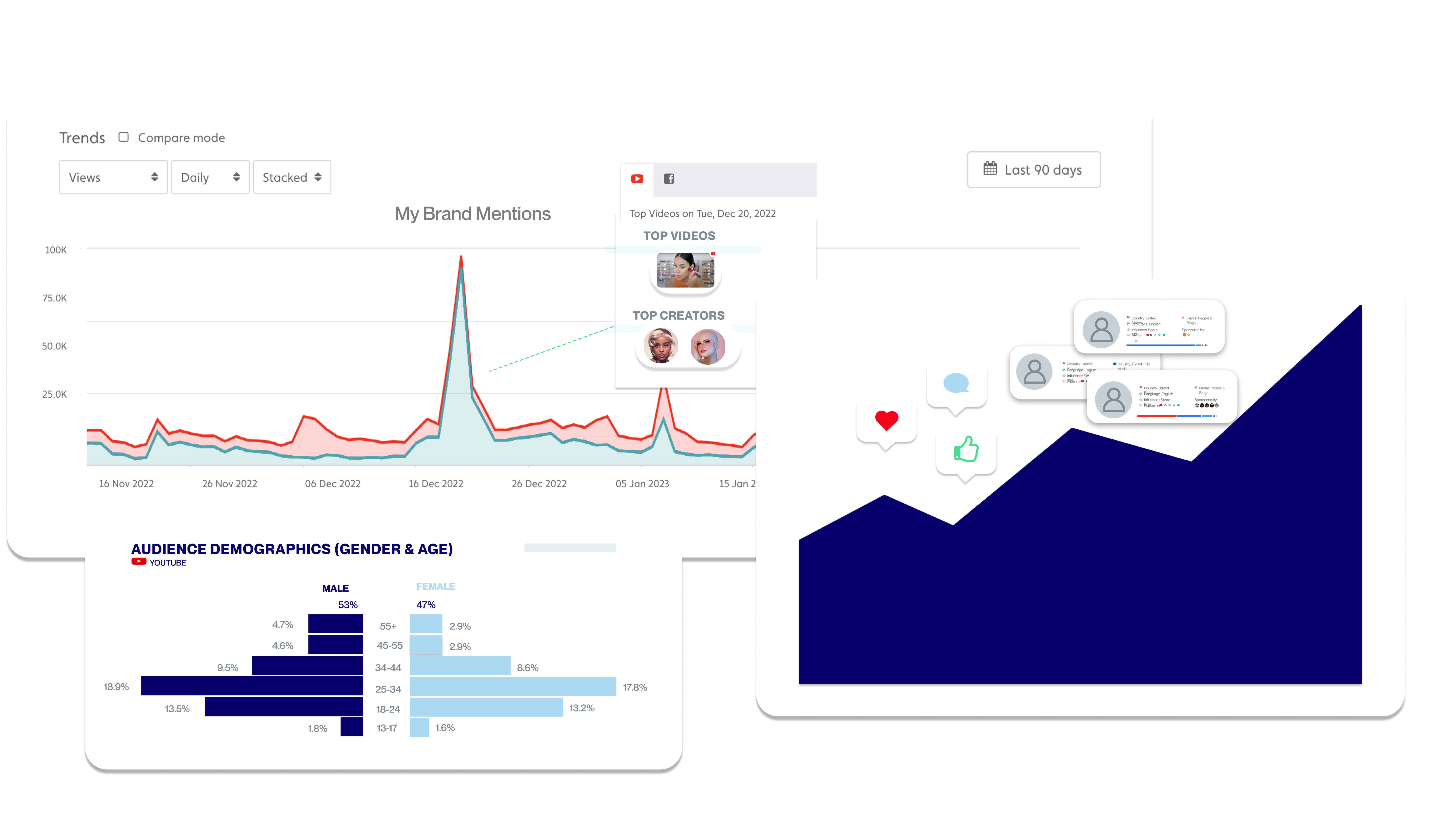
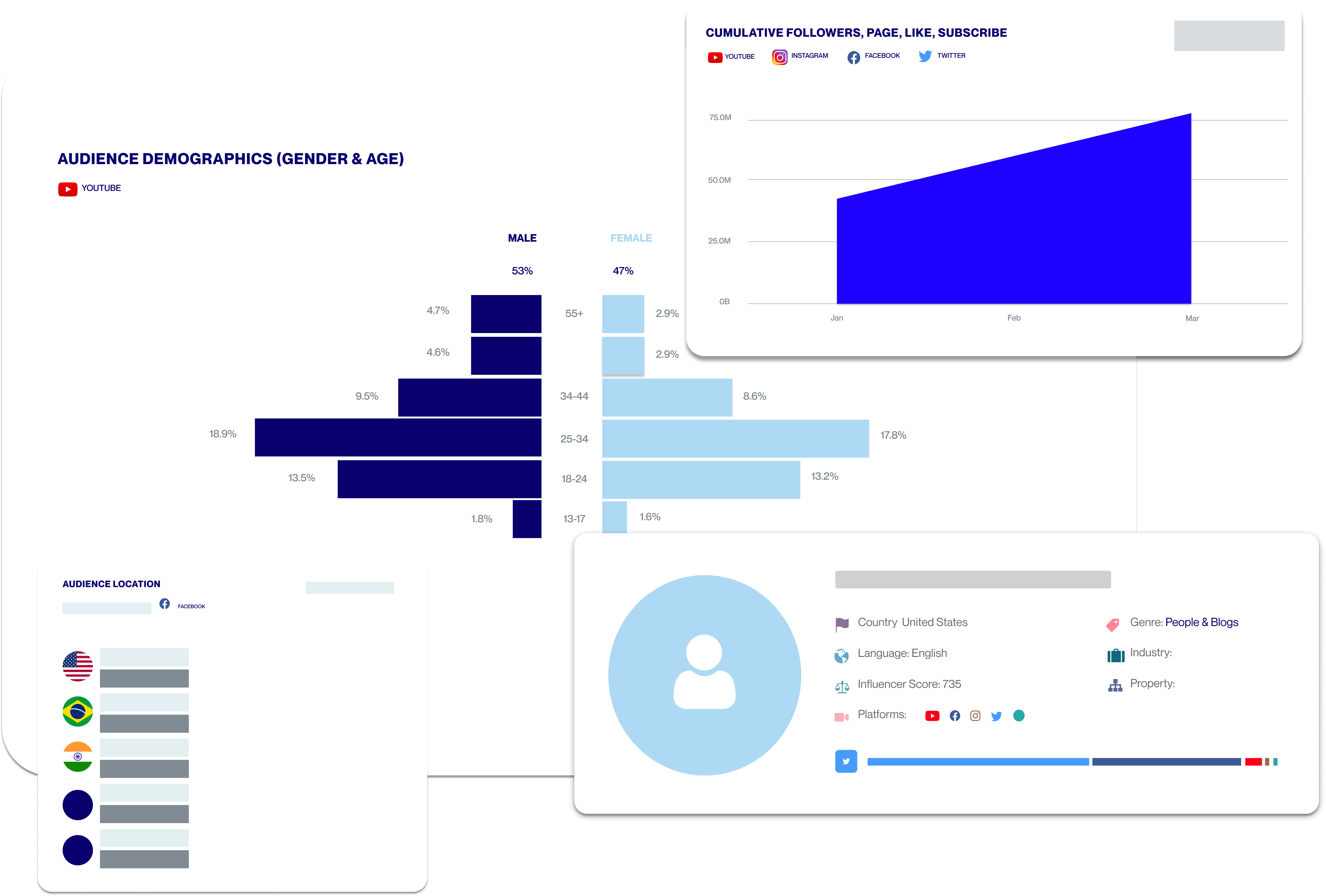
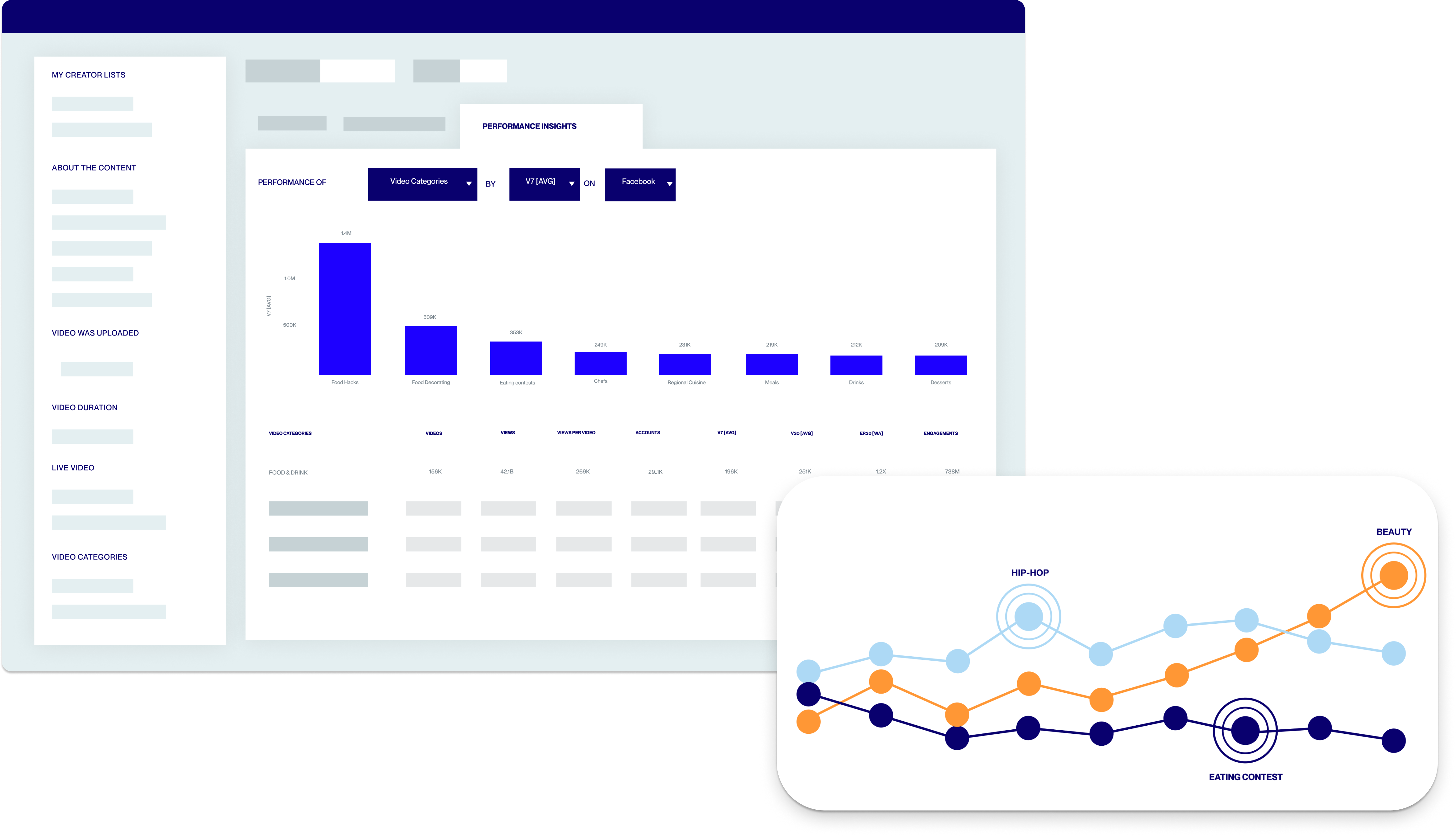
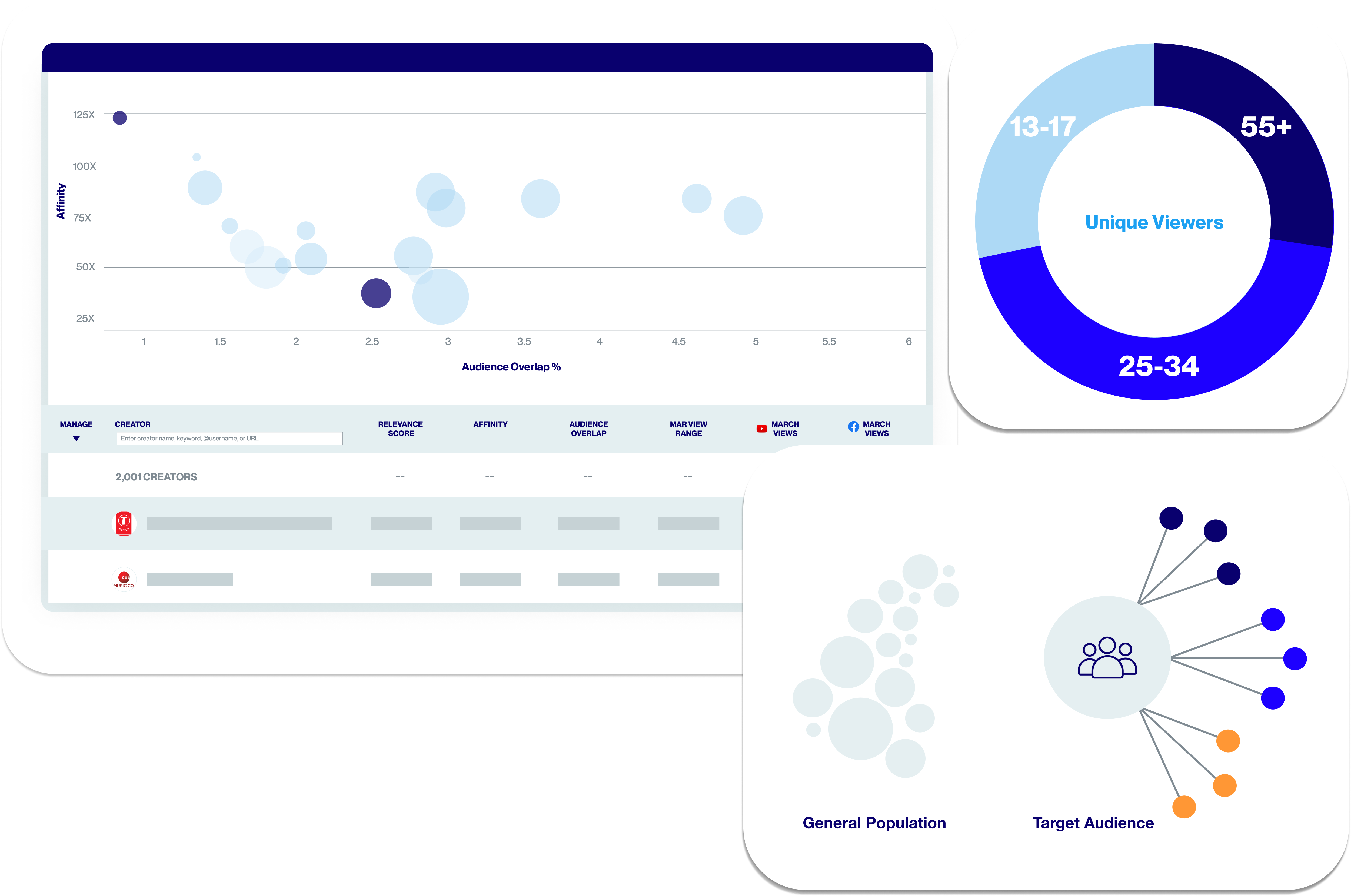
Social Listening for Video: Audience Analysis of the Silent Majority
Synergize your site and social media strategy to harness their combined power and create a content ecosystem that drives loyalty and nurtures engagement.